GPU基准测试:2080 Ti vs V100 vs 1080 Ti vs Titan V 【搬运】

在深度学习实践中,很多人会经常问一个问题:什么是最好的深度学习GPU?在这篇文章中,我们将主要分析以下几款目前最优秀的GPU:
- RTX 2080 Ti
- RTX 2080
- GTX 1080 Ti
- Titan V
- Tesla V100
为了从中挑选出最佳GPU,我们会从定价、性能两个维度对它们进行分析。原文链接
实验结果
根据全面定性定量的实验结果,截至2018年10月8日,NVIDIA RTX 2080 Ti是现在最好的深度学习GPU(用单个GPU运行Tensoflow)。以单GPU系统的性能为例,对比其他GPU,它的优劣分别是:
- FP32时,速度比1080 Ti快38%;FP16时,快62%。在价格上,2080 Ti比1080 Ti贵25%
- FP32时,速度比2080快35%;FP16时,快47%。在价格上,2080 Ti比2080贵25%
- FP32时,速度是Titan V的96%;FP16时,快3%。在价格上,2080 Ti是Titan V的1/2
- FP32时,速度是Tesla V100的80%;FP16时,是Tesla V100的82%。在价格上,2080 Ti是Tesla V100的1/5
请注意,所有实验都使用Tensor Core(可用时),并且完全按照单个GPU系统成本计算。
深入分析
实验中,所有GPU的性能都是通过在合成数据上训练常规模型,测量FP32和FP16时的吞吐量(每秒处理的训练样本数)来进行评估的。为了标准化数据,同时体现其他GPU相对于1080 Ti的提升情况,实验以1080 Ti的吞吐量为基数,将其他GPU吞吐量除以基数计算加速比,这个数据是衡量两个系统间相对性能的指标。
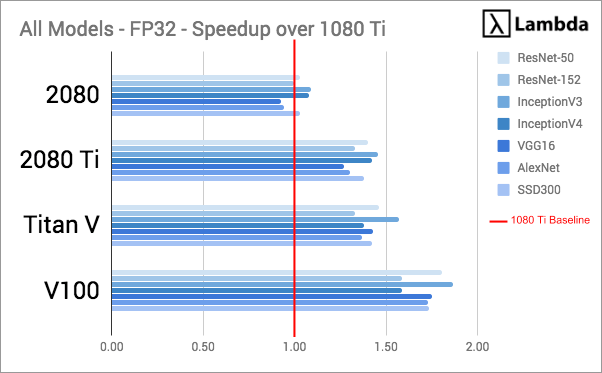
对上图数据计算平均值,同时按不同浮点计算能力进行分类,我们可以得到:
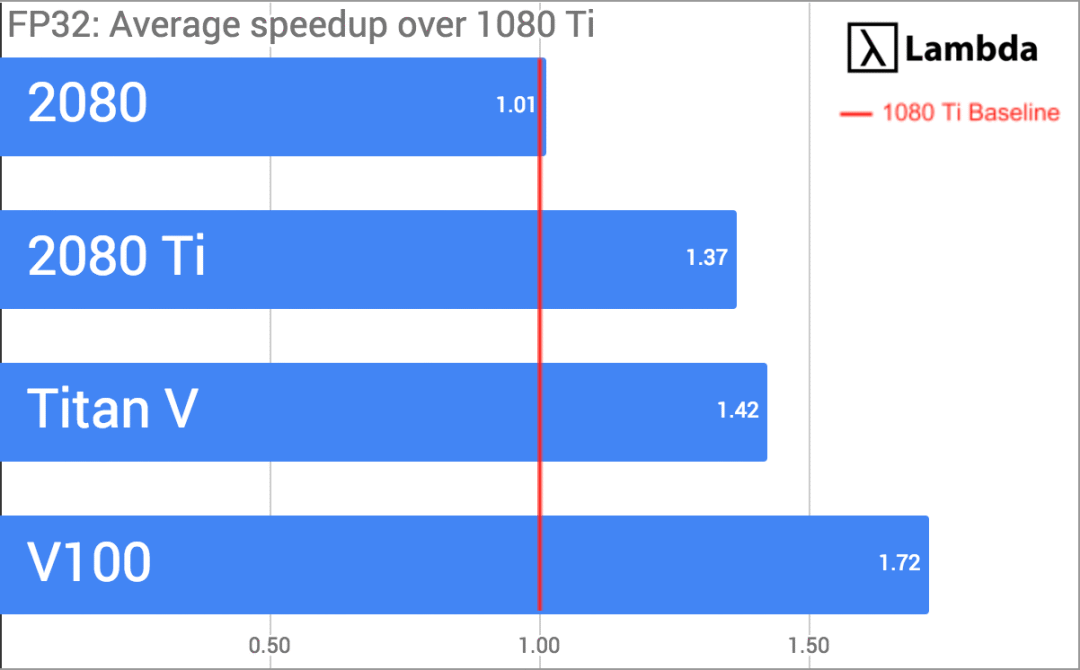
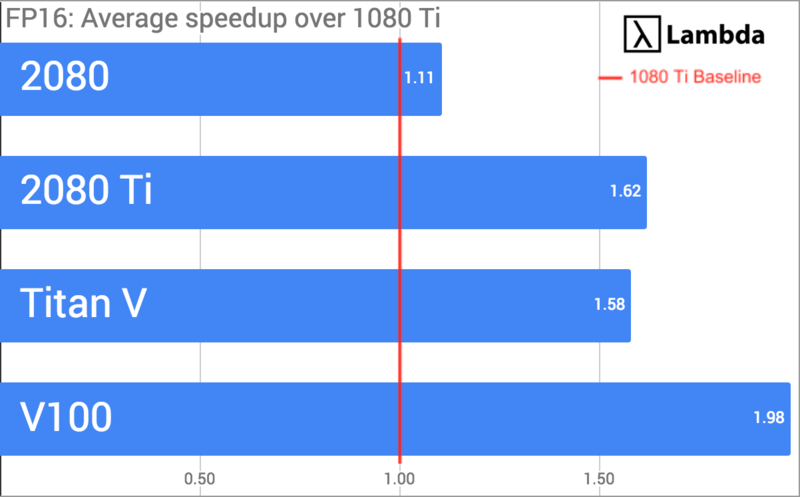
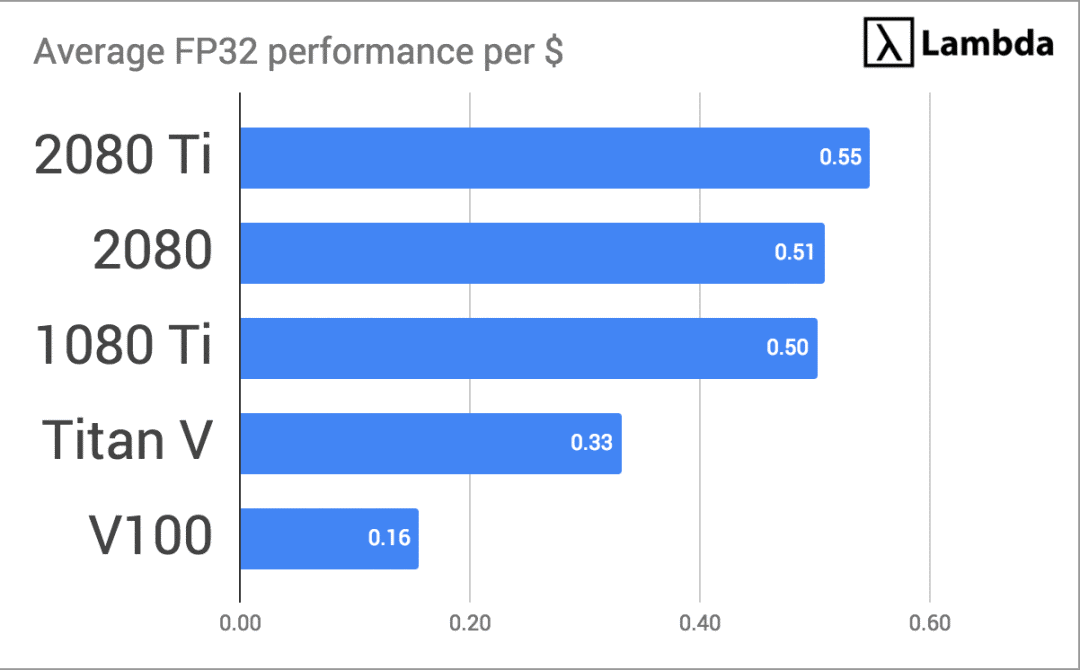
可以发现,2080的模型训练用时和1080 Ti基本持平,但2080 Ti有显著提升。而Titan V和Tesla V100由于是专为深度学习设计的GPU,它们的性能自然会比桌面级产品高出不少。最后,我们再将每个GPU的平均加速情况除以各自总成本:
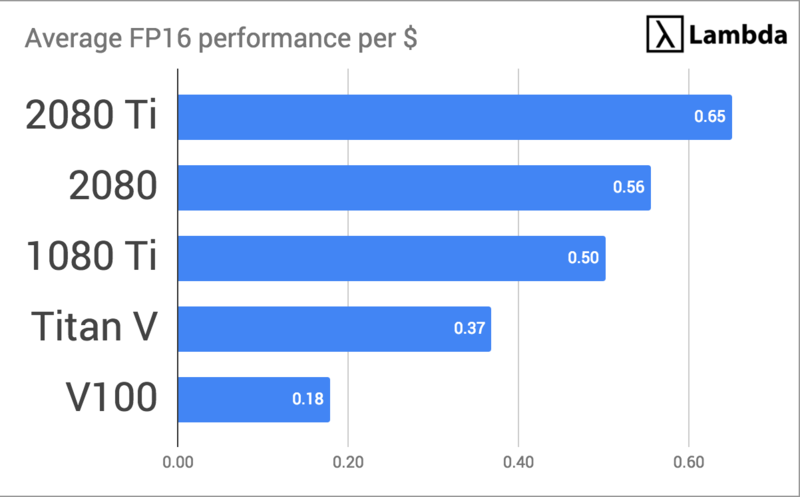
2080 Ti vs V100:2080 Ti真的那么快吗?
可能有人会有疑问,为什么2080 Ti的速度能达到Tesla V100的80%,但它的价格只是后者的八分之一?答案很简单,NVIDIA希望细分市场,以便那些有足够财力的机构/个人继续购买Tesla V100(约9800美元),而普通用户则可以选择在自己价格接受范围内的RTX和GTX系列显卡——它们的性价比更高。
除了AWS、Azure和Google Cloud这样的云服务商,个人和机构可能还是买2080 Ti更划算。但这不是说亚马逊、微软、Google这些公司“人傻钱多”,Tesla V100确实有一些其他GPU所没有的重要功能:
- 如果你需要FP64计算。如果你的研究领域是计算流体力学、N体模拟或其他需要高数值精度(FP64)的工作,那么你就得购买Titan V或V100s。
- 如果你对32 GB的内存有极大需求(比如11G的内存都不够存储模型的1个batch)。这类情况很少见,它面向的是想创建自己的模型体系架构的用户。而大多数人使用的都是像ResNet、VGG、Inception、SSD或Yolo这样的东西,这些人的占比可能不到5%。
面对2080 Ti,为什么还会有人买Tesla V100?这就是NVIDIA做生意的高明之处。
2080Ti是保时捷911,V100是布加迪威龙
V100有点像布加迪威龙,它是世界上最快的、能在公路上合法行驶的车,同时价格也贵得离谱。如果你不得不担心它的保险和维修费,那你肯定买不起这车。另一方面,RTX 2080 Ti就像一辆保时捷911,它速度非常快,操控性好,价格昂贵,但在炫耀性上就远不如前者。
毕竟如果你有买布加迪威龙的钱,你可以买一辆保时捷,外加一幢房子、一辆宝马7系、送三个孩子上大学和一笔客观的退休金。
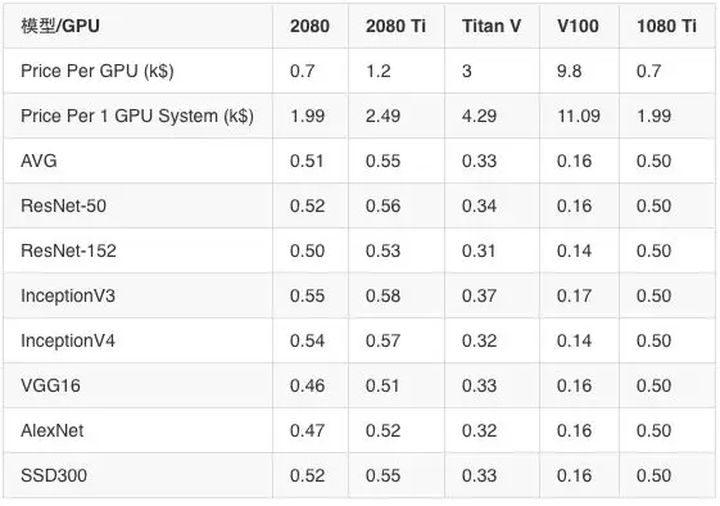
价格表现数据(加速/$1,000)FP32
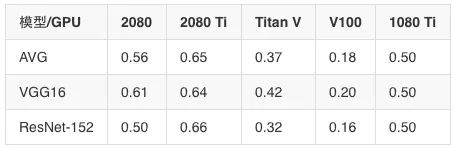
价格表现数据(加速/$1,000)FP16
实验方法
- 所有模型都在合成数据集上进行训练,这能将GPU性能与CPU预处理性能有效隔离开来。
- 对于每个GPU,对每个模型进行10次训练实验。测量每秒处理的图像数量,然后在10次实验中取平均值。
- 计算加速基准的方法是获取的图像/秒吞吐量除以该特定模型的最小图像/秒吞吐量。这基本上显示了相对于基线的百分比改善(在本实验中基准为1080 Ti)。
- 2080 Ti、2080、Titan V和V100基准测试中考虑到了Tensor Core。